나의 테크 역량을 개선하고 프로덕트의 완성도를 높이기 위해 할 수 있는 것들을 생각해보다가 AWS Bedrock을 직접 사용해보면 좋다는 생각을 했다. 따라서, Bedrock을 사용해 간단한 챗봇을 만들고자 한다. 실제로 다른 부서나 외부 파트너사에게 우리 부서에 대한 프로젝트를 문의할 때 약간의 피곤함을 느끼는데 챗봇 링크 하나 던져주고 해결할 수 있을 것 같아 챗봇을 만들기로 결정했다.
AWS Bedrock은 Meta, Mistral, Anthropic 같은 AI 회사의 다양한 고성능 FM을 단일 API를 통해 제공하는 관리형 서비스이다. 이 서비스를 통해 생성형 AI 어플리케이션을 구축하는 데 필요한 기능 세트를 활용할 수 있다. AWS Bedrock을 사용하기 전에 기본적인 세팅이 필요하지만 AWS 웹사이트 내 세팅 방법이 상세하게 안내되어 있어 생략하겠다. 세팅에는 대충 Bedrock, Cloud9,Lab Setup 정도가 요구된다. 세팅을 다했다면 Foundational concepts labs에서 Invoke API, converse API, Controlling response variability 같은 컨셉, 프레임워크, 서비스들을 미리 학습하는 것을 권장한다.
앞서 말한 세팅, 실습을 다했다면 이제 본격적으로 RAG를 곁들인 챗봇을 만들 준비가 되었다.
근데 RAG에 대해서 간단하게 설명하자면, RAG(Retrieval-Augmented Generation)은 인공지능 모델 중 하나로, 검색 기반 생성 방식을 의미한다. 이 방식은 텍스트 생성 시 기존의 정보 검색 시스템을 활용하여 더 정확하고 관련성 높은 답변을 생성한다. 특히, 대화형 AI 시스템에서 RAG를 활용하면 사용자 질문에 대한 더 정확한 답변을 제공할 수 있다. 즉, AI 답변 능력을 한층 더 향상시킨다.
챗봇 구현 순서는 아키텍처 구성 - 라이브러리 스크립트 작성 - Streamlit FE App 구현 - App 실행 순으로 진행하겠다.
아키텍처
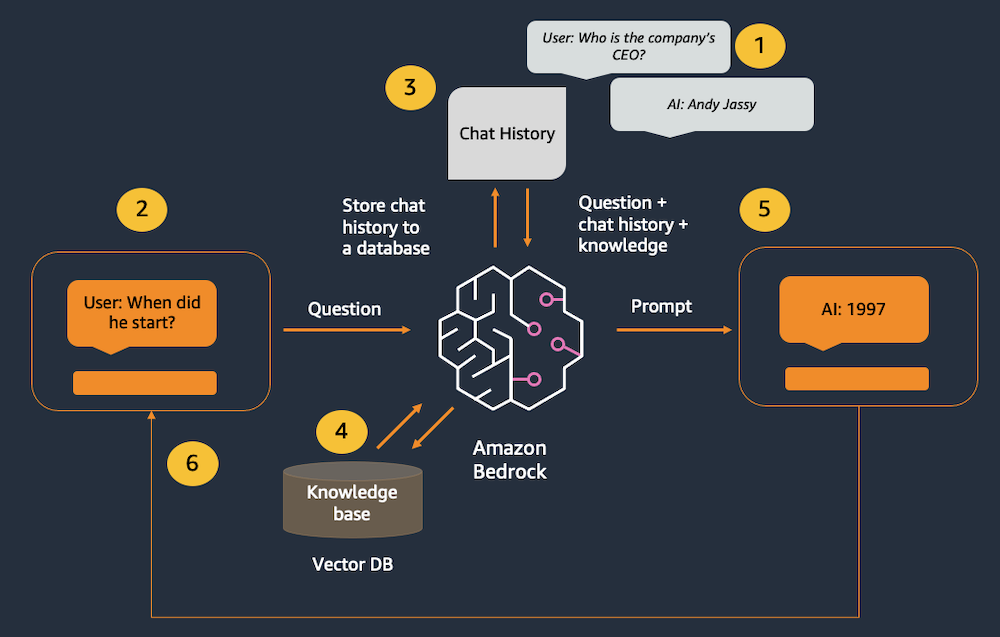
1. 채팅 메모리 객체(object)에서 과거의 채팅 내역을 추적한다.
2. 유저가 새로운 메시지를 입력한다.
3. 채팅 기록이 메모리 객체에서 검색되어 새 메시지 앞으로 추가된다.
4. 질문이 Amazon Titan 임베딩을 사용하여 벡터로 변환하고, 다음 벡터 DB에서 가장 가까운 벡터와 일치시킨다.
5. 결합된 기록, 지식, 새 메시지가 모델에 전송된다.
6. 모델의 응답이 사용자에게 표시된다.
즉, 과거 채팅 내역에서 유저와의 대화 문맥을 확인하고 새로운 메시지를 추가하고 문맥을 강화한다. 그런 다음 컴퓨터가 이해할 수 있도록 Amazon Titan을 활용하여 숫자 벡터로 변환을 한다. 그리고 다른 벡터들과 비교를 통해 가장 유사한 벡터, 즉 가장 관련성 있는 정보를 찾아낸다. 그리고 사용자에 보여지는 과정을 거치는 것이다.
라이브러리 스크립트
import itertools
import boto3
import chromadb
from chromadb.utils.embedding_functions import AmazonBedrockEmbeddingFunction
MAX_MESSAGES = 20
class ChatMessage(): #create a class that can store image and text messages
def __init__(self, role, text):
self.role = role
self.text = text
먼저 chroma vector DB를 사용하기 위해 호출하는 코드를 작성 후, MAX _MESSAGES는 20으로 설정했다. MAX_MESSAGES는 메모리에 보관되는 이전 채팅 메시지의 상한을 결정하는 것이다. 그리고 문자 메시지를 저장하는 class를 정의했다.
그 다음은 chroma DB에 연결하는 함수를 추가하고, 벡터 스토어에서 결과를 추가하는 함수를 사용했다.
def get_collection(path, collection_name):
session = boto3.Session()
embedding_function = AmazonBedrockEmbeddingFunction(session=session, model_name="amazon.titan-embed-text-v2:0")
client = chromadb.PersistentClient(path=path)
collection = client.get_collection(collection_name, embedding_function=embedding_function)
return collection
def get_vector_search_results(collection, question):
results = collection.query(
query_texts=[question],
n_results=4
)
return results
그 다음은 생성된 JSON을 정의하는데 사용한 도구 정의를 생성하는 함수와 메시지를 Converse API로 변환하는 함수를 추가했다. 그리고 Tool use 리퀘스트를 처리할 함수와 Streamlit FE 어플리케이션을 요청할 수 있는 함수를 추가했다. (코드 생략)
Streamlit FE app
import streamlit as st #all streamlit commands will be available through the "st" alias
import rag_chatbot_lib as glib #reference to local lib script
st.set_page_config(page_title="RAG Chatbot") #HTML title
st.title("RAG Chatbot") #page title
if 'chat_history' not in st.session_state: #see if the chat history hasn't been created yet
st.session_state.chat_history = [] #initialize the chat history
chat_container = st.container()
input_text = st.chat_input("Chat with your bot here") #display a chat input box
if input_text:
glib.chat_with_model(message_history=st.session_state.chat_history, new_text=input_text)
#Re-render the chat history (Streamlit re-runs this script, so need this to preserve previous chat messages)
for message in st.session_state.chat_history: #loop through the chat history
with chat_container.chat_message(message.role): #renders a chat line for the given role, containing everything in the with block
st.markdown(message.text) #display the chat content
필요한 것들을 import하고, HTML과 page title을 작성한다. 나는 그냥 "RAG Chatbot"으로 했다. 그리고 채팅 기록을 UI에 다시 렌더링 할 수 있는 코드를 추가해야 한다. 그렇지 않으면 새 채팅 메시지와 함께 이전 메시지가 사용자 인터페이스에서 사라진다. 채팅 입력 컨트롤을 추가할 때는 Claude 3을 사용했다. 그리고 마지막으로 반복문을 사용하여 이전 채팅 멧지를 렌더링하는 코드를 넣어두었다. 그러면 어플리케이션을 실행할 준비를 모두 마친 것이다.
App 실행
터미널에서 앱을 실행해주면 아래 사진처럼 RAG Chatbot의 GUI를 확인할 수 있다!

몇 가지 프롬프트를 테스트해봤다. 답변 전에는 야무진 로딩스피너도 작동되어 심심하지 않다.

AWS Bedrock을 처음 써봤는데 앞으로 인프라 구축&관리에 유용할 것 같은 느낌이 확실하게 들긴했다. 회사의 개발자들도 쉽게 구현이 가능할정도로 간편했고 나름 확장성이 있는 것 같다. 구현하면서 몇가지 사업 아이디어가 떠올랐는데 내일 회의에서 바로 건의해볼 생각이다. 이래서 이런 것들을 따라해보는 것이 좋은 것 같다.
'My Work > 웹 & 앱 서비스' 카테고리의 다른 글
| SEO (검색 엔진 최적화) 24년 버전_BERT를 곁들인 (12) | 2024.10.20 |
|---|---|
| AWS Bedrock : Prompt Engineering Labs (0) | 2024.08.13 |
| Sementic Search (시맨틱 검색)_토스는 똑똑해 (0) | 2024.08.04 |
| Ali Express 상품 리뷰를 통한 감정 모델 분석 (0) | 2024.06.21 |
| 모두의 주차장 서비스 개선하기 feat. 피처 벡터 (0) | 2024.06.07 |



