'한국복지패널데이터' 사용한 데이터 분석을 하겠다. 한국복지패널데이터는 한국보건사회연구원에서 가구의 경제활동을 연구한 자료로 경제 활동, 생활 실태, 복지 욕구 등 천여 개의 변수로 구성되어 있다.
필요한 데이터는 한국복지패널 사이트에서 다운 받으면 된다.
install.packages("foreign") # foreign 패키지 설치
library(foreign) # SPSS 파일 로드
library(dplyr) # 전처리
library(ggplot2) # 시각화
library(readxl) # 엑셀 파일 불러오기
# 데이터 불러오기
file_path <- "(파일 저장 위치)/Koweps_hpc10_2015_beta9.sav"
raw_welfare <- read.spss(file_path, to.data.frame = TRUE)
welfare <- raw_welfare
필요한 패키지를 설치하고 데이터를 불러온다. 그리고 원활한 분석을 위해 사용한 변수를 쉬운 이름으로 바꾸었다.
welfare <- rename(welfare,
sex = h10_g3, # 성별
birth = h10_g4, # 태어난 연도
marriage = h10_g10, # 혼인 상태
religion = h10_g11, # 종교
income = p1002_8aq1, # 월급
code_job = h10_eco9, # 직종 코드
code_region = h10_reg7) # 지역 코드
해당 데이터 성별에서는 '9'로 표현된 데이터 값이 있는 데, 이것은 이상치이므로 9 대신 NA를 부여하겠다.
# 이상치 결측 처리
welfare$sex <- ifelse(welfare$sex == 9, NA, welfare$sex)
# 결측치 확인
table(is.na(welfare$sex))
# 출력값
FALSE
16664
또한, income도 대다수를 차지하는 0~1000 사이만 표현되도록 설정했다. 그리고 월급을 모름/무응답으로 답한 경우, 9999로 되어 있기 때문에 이 값도 NA로 대체했다.
qplot(welfare$income) + xlim(0, 1000
welfare$income <- ifelse(welfare$income %in% c(0, 9999), NA, welfare$income)
다음은 나이에 따른 월급 평균표를 만들고 그래프로 Visualization을 해보겠다. 전처리 과정은 생략하겠다.
# 나이에 따른 월급 평균표
age_income <- welfare %>%
filter(!is.na(income)) %>%
group_by(age) %>%
summarise(mean_income = mean(income))
head(age_income)
# 출력값
# A tibble: 6 × 2
age mean_income
<dbl> <dbl>
1 20 121.
2 21 106.
3 22 130.
4 23 142.
5 24 134.
6 25 145.
# 그래프 만들기
ggplot(data = age_income, aes(x = age, y = mean_income)) + geom_line()
표에서 확인 가능하듯이 50대에서 가장 많은 월급을 받고 나이가 들면서 월급이 적어진다는 것을 확인할 수 있다.
다음은 연령대별 월급 평균표를 만들고 그래프로도 만들겠다. 초년은 30대 미만, 중년은 30세 ~ 59세, 노년은 60세 이상으로 구성했다. 그리고 막대그래프로 표현하겠다.
# 연령대 구성
welfare <- welfare %>%
mutate(ageg = ifelse(age < 30, "young",
ifelse(age <= 59, "middle", "old")))
table(welfare$ageg)
# 출력값
middle old young
6051 6279 4334
# 막대그래프로 표현
ggplot(data = ageg_income, aes(x = ageg, y = mean_income)) +
geom_col() +
scale_x_discrete(limits = c("young", "middle", "old"))
이번에는 나이 및 성별 월급 차이를 분석해보겠다. 남자를 male 초록색으로 표현하고 여자를 female 빨간색으로 표현한 꺾은선 그래프이다.
# 성별 연령별 월급 평균표 만들기
sex_age <- welfare %>%
filter(!is.na(income)) %>%
group_by(age, sex) %>%
summarise(mean_income = mean(income))
# 그래프 만들기
ggplot(data = sex_age, aes(x = age, y = mean_income, col = sex)) + geom_line()
이번에는 직업별 월급 평균표를 만들고 그래프를 만들 것이다. 마찬가지로 전처리 과정은 생략할 것이다. 직업이 없거나 월급이 없는 사람은 분석 대상이 아니므로 제외한 다음, 어떤 직업의 월급이 많은지 내림차순으로 정렬하고 상위 10개를 추출할 것이다.
# 직업이 없거나 월급이 없는 사람 제외
job_income <- welfare |>
filter(!is.na(job) & !is.na(income)) |>
group_by(job) |>
summarise(mean_income = mean(income))
# 내림차순 구성 및 top 10 구성
top10 <- job_income |>
arrange(desc(mean_income)) |>
head(10)
top10
# 출력값
# A tibble: 10 × 2
job mean_income
<chr> <dbl>
1 금속 재료 공학 기술자 및 시험원 845.
2 의료진료 전문가 844.
3 의회의원 고위공무원 및 공공단체임원 750
4 보험 및 금융 관리자 726.
5 제관원 및 판금원 572.
6 행정 및 경영지원 관리자 564.
7 문화 예술 디자인 및 영상 관련 관리자 557.
8 연구 교육 및 법률 관련 관리자 550.
9 건설 전기 및 생산 관련 관리자 536.
10 석유 및 화학물 가공장치 조작원 532.
# 그래프 구성
ggplot(data = top10, aes(x = reorder(job, mean_income), y = mean_income)) +
geom_col() +
coord_flip()
다음은 남성 직업 빈도표를 만들고 그래프화 하겠다.
# 남성 직업 빈도 상위 10개 추출
job_male <- welfare |>
filter(!is.na(job) & sex == "male") |>
group_by(job) |>
summarise(n = n()) |>
arrange(desc(n)) |>
head(10)
job_male
# 출력값
# A tibble: 10 × 2
job n
<chr> <int>
1 작물재배 종사자 640
2 자동차 운전원 251
3 경영관련 사무원 213
4 영업 종사자 141
5 매장 판매 종사자 132
6 제조관련 단순 종사원 104
7 청소원 및 환경 미화원 97
8 건설 및 광업 단순 종사원 95
9 경비원 및 검표원 95
10 행정 사무원 92
# 남성 직업 빈도 상위 10개 직업
ggplot(data = job_male, aes(x = reorder(job, n), y = n)) +
geom_col() +
coord_flip()
다음은 종교 유무에 따른 이혼율 표를 만들고 마찬가지로 그래프화하겠다. 전처리 과정은 생략하겠다. 종교 우무 및 결혼 상태별로 나눠 빈도를 구한 뒤 종교 유무 집단의 전체 빈도로 나눠 비율을 구할 것이다. 비율은 round()를 이용해 소수점 첫째 자리까지 표현한다. 그런 다음 이혼에 해당하는 값만 추출해서 이혼율 표를 만들 것이다.
religion_marriage <- welfare |>
filter(!is.na(group_marriage)) |>
group_by(religion, group_marriage) |>
summarise(n = n()) |>
mutate(tot_group = sum(n),
pct = round(n/tot_group*100, 1))
religion_marriage
# 이혼 추출
divorce <- religion_marriage |>
filter(group_marriage == "divorce") |>
select(religion, pct)
divorce
# 출력값
religion pct
<chr> <dbl>
1 no 8.3
2 yes 7.2
ggplot(data = divorce, aes(x = religion, y = pct)) + geom_col()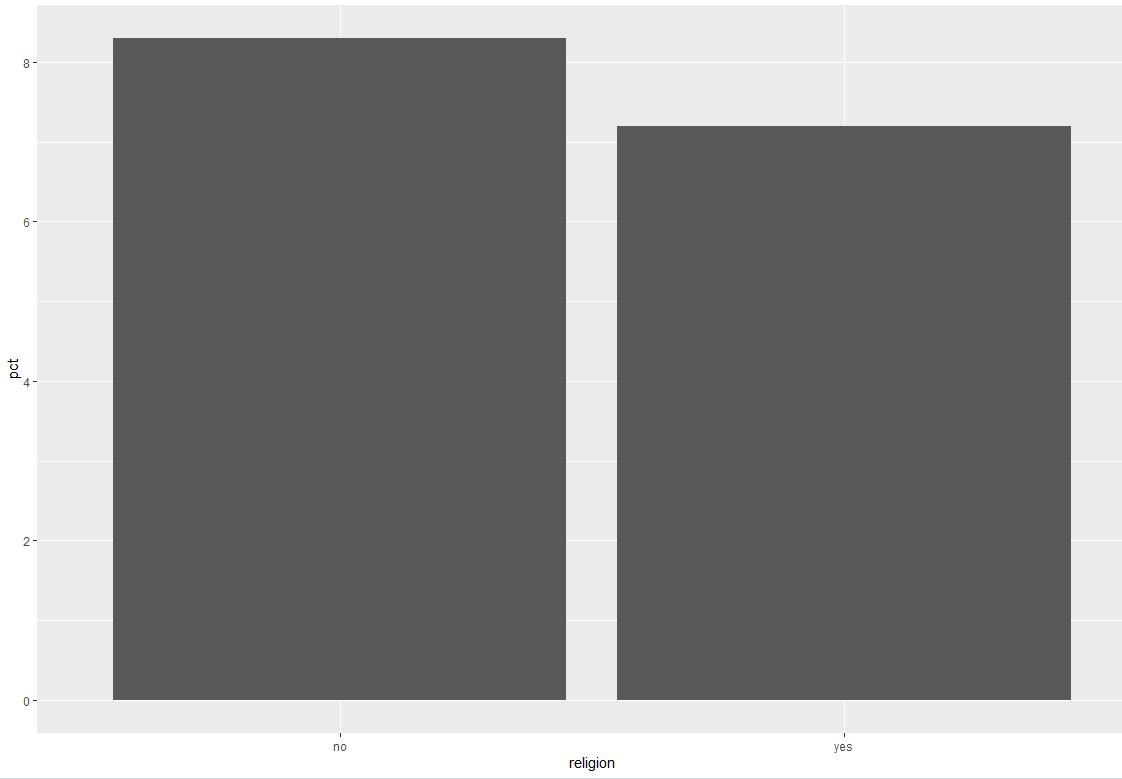
다음은 지역별 연령대 비율표를 만들 것이다. 마찬가지로 전처리 과정은 생략할 것이다.
# 지역별 연령대 비율표
region_ageg <- welfare |>
group_by(region, ageg) |>
summarise(n = n()) |>
mutate(tot_group = sum(n),
pct = round(n/tot_group*100, 2))
head(region_ageg)
# 출력값
region ageg n tot_group pct
<chr> <chr> <int> <int> <dbl>
1 강원/충북 middle 418 1257 33.2
2 강원/충북 old 554 1257 44.1
3 강원/충북 young 285 1257 22.7
4 광주/전남/전북/제주도 middle 950 2922 32.5
5 광주/전남/전북/제주도 old 1230 2922 42.1
6 광주/전남/전북/제주도 young 742 2922 25.4
# 그래프
ggplot(data = region_ageg, aes(x = region, y = pct, fill = ageg)) +
geom_col() +
coord_flip()
'My Work > Data Literacy' 카테고리의 다른 글
| R 공부 (8편) - 쉽게 배우는 R 데이터 분석 (0) | 2024.08.05 |
|---|---|
| R 공부 (7편) - 쉽게 배우는 R 데이터 분석 (0) | 2024.07.28 |
| R 공부 (5편) - 쉽게 배우는 R 데이터 분석 (2) | 2024.07.15 |
| R 공부 (4편) - 쉽게 배우는 R 데이터 분석 (1) | 2024.07.14 |
| R 공부 (3편) - 쉽게 배우는 R 데이터 분석 (0) | 2024.07.10 |


