😵💫문제
주말에 차를 가지고 서울에서 돌아다닐 때, 항상 짜증나는 부분이 주차 문제이다. 특히, 토요일에는 무료 주차장이나 값싼 주차장을 찾기 어렵고 기껏 찾아내도 주차 자리가 없어서 힘들었던 적이 많다. 실제로, 저번주 주말에 서울대입구에서 주차를 하기 위해 4곳의 주차장을 방문했으나 모두 주차를 할 수 없었다.
'모두의 주차장'을 통해 주차장을 미리 찾아도 잔여 주차 자리가 없는 경우도 많았으며, 내가 주차하고 싶은 시간에 대한 정확한 요금 계산을 운전 중에 암산으로 해야했다.
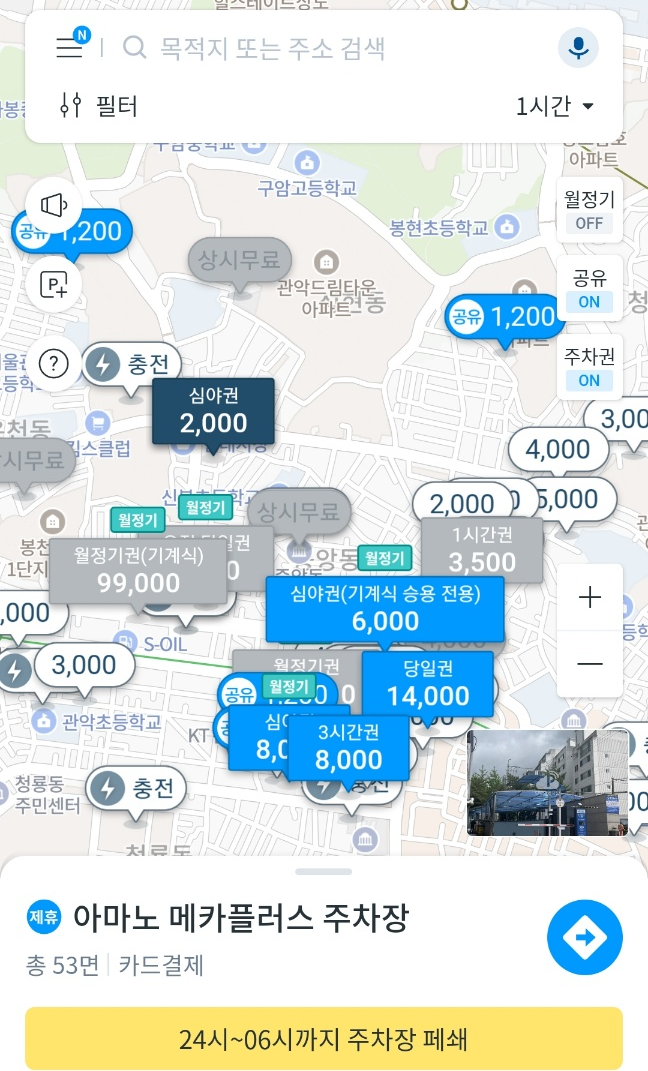
실제로 모두의 주차장 UI를 보면 실시간 주차 가능 자리는 표시되지 않는다. 더불어, 만약 내가 30분이나 1시간이 아닌 애매한 시간, 예를 들어 2시간 45분정도만 주차를 하고자 할 때, 어느 주차장이 더 '가성비'인지 찾기가 어렵다.
즉, 나는 실시간 주차 가능 자리를 확인하고 싶고 어떤 주차장이 가성비 주차인지 확인하고 싶다.
💻문제 해결 준비
내가 생각하는 문제를 해결하기 위해 서울시에 제공하는 API를 사용할 것이다.

서울 열린데이터 광장의 "서울시 시영주차장 실시간 주차대수 정보" API (링크)
: 감사하게도 서울시에서는 시영주차장에서 한해 해당 시영주차장에 대한 여러가지 정보를 제공한다. 주차장명, 주소, 주차장 종료, 주차장 운영 시간, 주차장 전화번호, 주차 가격, 야간 개방 여부 등 내가 필요로 하는 자료를 모두 제공한다. 특히, 실시간 주차 가능 자리 수를 알려주기 때문에 내가 원하는 정보를 실시간으로 알아낼 수 있다.
서울 열린데이터 광장의 API를 활용하기 위해서는 인증 Key를 발급받아야 한다. 누구나 쉽게 발급 받을 수 있으며, 발급을 신청하면 바로 인증 Key를 확인할 수 있기 때문에 발급 과정을 글에서는 다루지 않겠다.
🎁 문제 해결
그럼 지금 내가 주차가 가능한 최적의 주차장 3개를 실시간으로 찾아보자.
내가 실제로 주말 야간에 사용할 코드이기 때문에 코드에 대한 요구사항은 아래와 같이 구성했다.
1. 주말에도 운영하는 주차장
2. 야간(오후 6시 ~ 9시)에도 운영하는 주차장
3. 내가 주차장에 도착했을 때, 여유 있게 주차가 가능할 수 있도록 주차 가능 차량 수가 10대 이상인 주차장
4. 가성비 주차장 (무료가 최고!)
5. 지역은 관악구로 한정 (내가 주차를 하고 싶은 지역)
요구사항에 따라 필요한 데이터를 파악했다. 정확한 출력명과 출력 설명은 캡쳐화면처럼 서울 열린데이터 광장 내에서 확인 가능한다.

PARKING_NAME(주차장 명), CUR_PARKING(현재 주차 차량 수), CAPACITY(총 주차면), PAY_YN(유무료 구분), RATES(기본 주차 요금), TIME_RATE(기본 주차 시간(분 단위)), ADD_RATES(추가 단위 요금), ADD_TIME_RATES(추가 단위 시간(분 단위)), WEEKENT_BEGIN_TIME(주말 운영 시작 시각), WEEKEND_END_TIME(주말 운영 종료 시각), QUE_STATUS(주차현황 정보 제공 여부)
그리고 나의 요구사항에 맞게 조건문을 만들고 제일 가격이 싼 3개의 주차장을 출력하도록 코드를 작성했다.
import pandas as pd
import numpy as np
import requests
from xml.etree import ElementTree
import time
# 시작 시간 기록
start_time = time.time()
# 데이터 요청 URL
url = "http://openapi.seoul.go.kr:8088/(인증키)/xml/GetParkingInfo/1/1000/관악구"
# XML 데이터 요청
response = requests.get(url)
tree = ElementTree.fromstring(response.content)
# XML 데이터를 Pandas DataFrame으로 변환
rows = []
for row in tree.findall('.//row'):
rows.append({
"PARKING_NAME": row.find('PARKING_NAME').text,
"CUR_PARKING": int(row.find('CUR_PARKING').text),
"CAPACITY": int(row.find('CAPACITY').text),
"PAY_YN": row.find('PAY_YN').text,
"RATES": int(row.find('RATES').text if row.find('RATES').text else 0),
"TIME_RATE": int(row.find('TIME_RATE').text if row.find('TIME_RATE').text else 0),
"ADD_RATES": int(row.find('ADD_RATES').text if row.find('ADD_RATES').text else 0),
"ADD_TIME_RATE": int(row.find('ADD_TIME_RATE').text if row.find('ADD_TIME_RATE').text else 0),
"WEEKEND_BEGIN_TIME": row.find('WEEKEND_BEGIN_TIME').text,
"WEEKEND_END_TIME": row.find('WEEKEND_END_TIME').text,
"QUE_STATUS": row.find('QUE_STATUS').text
})
df = pd.DataFrame(rows)
# NumPy 배열로 변환
parking_name = np.array(df['PARKING_NAME'])
cur_parking = np.array(df['CUR_PARKING'])
capacity = np.array(df['CAPACITY'])
pay_yn = np.array(df['PAY_YN'])
rates = np.array(df['RATES'])
time_rate = np.array(df['TIME_RATE'])
add_rates = np.array(df['ADD_RATES'])
add_time_rate = np.array(df['ADD_TIME_RATE'])
weekend_begin_time = np.array(df['WEEKEND_BEGIN_TIME'])
weekend_end_time = np.array(df['WEEKEND_END_TIME'])
que_status = np.array(df['QUE_STATUS'])
# 조건 1: 주차 현황 정보 제공 여부가 '1'
condition_1 = que_status == '1'
# 조건 2: 현재 주차 차량수가 10 이상
condition_2 = cur_parking >= 10
# 조건 3: 운영 시간 1800 ~ 2100 포함
condition_3 = (weekend_begin_time <= '1800') & (weekend_end_time >= '2100')
# 모든 조건을 만족하는 주차장 필터링
valid_indices = np.where(condition_1 & condition_2 & condition_3)[0]
# 조건 4: 요금 계산 (무료 우선, 유료일 경우 저렴한 순)
prices = np.zeros(len(valid_indices))
for i, idx in enumerate(valid_indices):
if pay_yn[idx] == 'N':
prices[i] = 0
else:
prices[i] = rates[idx] + (180 // time_rate[idx]) * add_rates[idx]
# 가격 순으로 정렬하여 3개 선택
sorted_indices = valid_indices[np.argsort(prices)][:3]
# 결과 출력
for i, idx in enumerate(sorted_indices):
print(f"{i+1}. {parking_name[idx]} / 예상 요금: {prices[np.where(valid_indices == idx)[0][0]]}원 / 주차 가능 자리: {capacity[idx] - cur_parking[idx]}")
# 종료 시간 기록
end_time = time.time()
# 총 실행 시간 출력
print(f"코드 실행 시간: {end_time - start_time:.4f}초")
해당 코드를 실행해보니 관악구 내 주말 야간(오후 6시 ~ 9시)에 주차가 가능한(10대 이상) 가성비 주차장은 아래와 같았다.
출력 결과 :
신대방역 공영주차장(시) / 예상 요금: 9620원 / 주차 가능 자리: 24
구로디지털단지역(상) 공영주차장(시) / 예상 요금: 9620원 / 주차 가능 자리: 17
이렇게 원하는 주차 시간, 주차 가능 여부에 따라 최적의 주차장을 찾는 일을 쉽게 만들었다. 사용하는 API에는 주차장의 주소값도 포함되어 있어 내가 원하는 지역을 한정할 수도 있다. 또한, 텔레그램 봇이나 Chat GPT 앱을 사용해서 코드를 원할 때 실행하게 한다면 확장성을 더욱 올라갈 것이다.
이제 위험하게 운전하면서 주차 가능한 주차장을 찾지말자👍👍
⚽추가 고민
실시간으로 주차장 가격과 주차 가능 대수를 파악할 수 있게 되니 궁금증이 하나 더 늘게 되었다. 과연, "시영주차장의 가격은 합리적일까?" 라는 고민이었다.
앞서 말한대로 소비자는 제일 합리적인 가격을 보유한 주차장을 선호한다. 하지만, 주차 시간이 계산하기 어려울 경우, 해당 주차장이 저렴한지 비싼지 계산하기 어렵다. 보통 주차장의 요금제는 최초 시간(30분 내지 1시간)에 대한 최초 요금과 추가 시간(5분 내지 10분)에 대한 추가 요금으로 이루어져 있다. 따라서, 1시간을 기준으로 해당 주차장이 합리적인 가격대인지를 알아보기 위해 'Feature Vector' 라는 개념을 활용할 것이다.
Feature Vector는 데이터의 중요한 특성들을 수치화하여 하나의 벡터로 나타낸 것이다. 이는 머신러닝 및 데이터 과학에서 중요한 역할을 하며, 모델이 학습하고 예측할 수 있도록 데이터를 표현한다. 즉, Feature Vector을 생성하여 주차장 점수를 계산하고 가성비인 합리적인 주차장을 도출해낼 것이다.
import requests
import xml.etree.ElementTree as ET
# API 요청 URL (범위를 1에서 50으로 확대)
url = "http://openapi.seoul.go.kr:8088/(API 키)/xml/GetParkingInfo/1/1000/관악구"
# API 요청 및 응답 데이터 파싱
response = requests.get(url)
root = ET.fromstring(response.content)
# 필요한 데이터 추출 및 피처 벡터 생성
parking_data = []
for row in root.findall('row'):
if row.find('OPERATION_RULE').text == '1' and row.find('PAY_YN').text == 'Y':
parking_code = row.find('PARKING_CODE').text
parking_name = row.find('PARKING_NAME').text
capacity = int(row.find('CAPACITY').text)
weekday_begin_time = int(row.find('WEEKDAY_BEGIN_TIME').text)
weekday_end_time = int(row.find('WEEKDAY_END_TIME').text)
rates = int(row.find('RATES').text)
time_rate = int(row.find('TIME_RATE').text)
hourly_rate = rates * (60 // time_rate)
parking_data.append({
'parking_code': parking_code,
'parking_name': parking_name,
'capacity': capacity,
'weekday_begin_time': weekday_begin_time,
'weekday_end_time': weekday_end_time,
'hourly_rate': hourly_rate
})
# 중복 제거
unique_parking_data = {v['parking_code']: v for v in parking_data}.values()
# 주차장 점수 계산
def calculate_score(parking):
capacity_score = parking['capacity']
operating_time = parking['weekday_end_time'] - parking['weekday_begin_time']
operating_time_score = operating_time // 100 # 운영 시간 점수를 100으로 나눠서 사용
hourly_rate_score = 10000 - parking['hourly_rate'] # 요금 점수를 10000에서 뺀 값으로 사용
return capacity_score + operating_time_score + hourly_rate_score
# 점수 기반 정렬 및 상위 3개 주차장 선택
sorted_parking_data = sorted(unique_parking_data, key=calculate_score, reverse=True)[:3]
# 결과 출력
for i, parking in enumerate(sorted_parking_data, 1):
print(f"{i}. 주차장 코드: {parking['parking_code']}, 주차장 이름: {parking['parking_name']}, 1시간 요금: {parking['hourly_rate']}원, 점수: {calculate_score(parking)}")
점수에 영향을 주는 변수들은 아래와 같이 구성했다.
- 운영 시간이 길고 가격이 싸면 합리적이다.
- 주차장 공간이 많은데 가격이 싸면 합리적이다.
- 기본 요금이 싸면 합리적이다.
출력 결과 :
주차장 코드: 1163833, 주차장 이름: 봉천복개3 공영주차장(시), 1시간 요금: 2640원, 점수: 7371
주차장 코드: 1366590, 주차장 이름: 신대방역 공영주차장(시), 1시간 요금: 3120원, 점수: 6964
주차장 코드: 1366593, 주차장 이름: 구로디지털단지역(상) 공영주차장(시), 1시간 요금: 3120원, 점수: 6924
🎢 마무리
실제로 운전할 때 겪었던 불편함을 해소하기 위해 서울시에서 제공하는 API를 활용해서 모두의 주차장의 문제점을 해결하면서 서비스를 개선하는 시간을 갖췄다. 더불어서, 간단하게 Feature Vector 개념을 활용해서 주차장의 합리성까지 따져보았다. 이런 시간을 가질수록 데이터를 자유자재로 사용할 수 있는 세대에 태어난 것에 감사함을 느끼기도 한다. 더불어 내가 사용하는 서비스를 직접 개선하는 습관은 과거의 나와 차이를 만들어내는 것 같다.
'My Work > Data Literacy' 카테고리의 다른 글
| Ali Express 상품 리뷰를 통한 감정 모델 분석 (0) | 2024.06.21 |
|---|---|
| 프로그래머스 연습문제 풀이 (0) | 2023.12.09 |
| 필수 SQL 개념 - (3/3편) (0) | 2023.11.30 |
| 필수 SQL 개념 - (2/3편) (0) | 2023.11.29 |
| 필수 SQL 개념 - (1/3편) (1) | 2023.11.28 |


