문제 정의 💥
야구나 홈쇼핑 같은 라이브 방송 중에 실시간으로 송출되는 댓글들이 있다. 주로 시청자 참여를 촉진하고, 실시간 상호작용을 통해 방송의 생동감을 높이기 위함이다. 하지만, 안타깝게도 '그 의도'와 벗어난 댓글들이 올라올 때가 있다. 부정적인 반응이나 교묘하게 돌려까는(?)식의 댓글들이 화면에 노출되기도 한다.
즉, 그러한 문제를 방지하고, 라이브 방송의 품질을 유지하기 위해 선제적으로 부적절한 댓글을 필터링하는 시스템이 필요하다. 따라서, 이번에는 BERT 모델을 활용하여 실시간 댓글의 감정을 분석하고, 부정적인 댓글을 사전에 예측하여 필터링하는 것을 목표로 모델을 구현했다.
근데 왜 BERT?
BERT는 양방향성을 가지는 언어 모델로, 문맥을 깊이 이해할 수 있기 때문이다. 일반적인 RNN이나 LSTM 모델은 텍스트를 순차적으로 처리하여 이전 단어의 정보만을 활용하는 반면, BERT는 입력 텍스트의 양쪽 문맥을 모두 참조하여 더 풍부한 의미를 추출할 수 있다. 특히 댓글과 같은 짧은 텍스트에서 중요한 역할을 한다.
문제 해결을 위한 사전 준비 💌
실시간으로 얻을 수 있는 댓글이나 반응이 없어서 AliExpress의 상품 리뷰 데이터셋을 활용할 것이다. 데이터셋 분석을 통해 긍정적 / 부정적 / 중립적 감정을 분류하는 모델을 개발할 예정이다.
Kaggle(카글 링크)에서 데이터셋을 구해 필요없는 컬럼을 제거하고 리뷰 파일을 재구성했다.
많은 컬럼들이 있지만 내가 사용할 컬럼들은 아래와 같다.
- buyerName: The name or identifier of the buyer who submitted the evaluation.
- buyerCountry: The count(ry of the buyer who submitted the evaluation.
- Evaluation: The evaluation or rating given by the buyer for the product.
- buyerTranslationFeedback: Feedback related to translation services if applicable.
- downVoteCount: The count of downvotes received for the evaluation.
- upVoteCount: The count of upvotes received for the evaluation.
- evalData: Date of the evaluation.
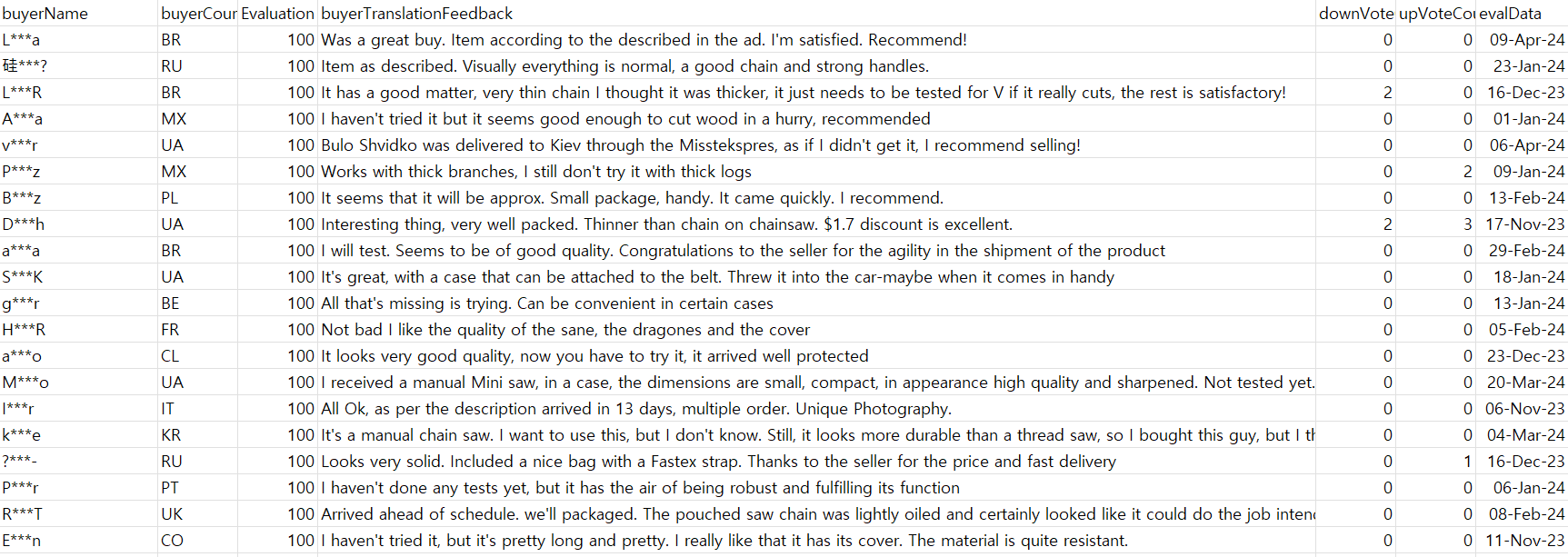
상품에 대한 평가 점수, 상품 리뷰(번역본), 리뷰에 대한 추천/비추천 수, 리뷰 등록 날짜 등으로 리뷰 CSV 파일을 재구성했다. AliExpress 같은 경우, 전 세계를 타겟으로 서비스를 하다보니 리뷰자의 국적이 다양해서 리뷰의 언어도 다양했다. 따라서, 기존 리뷰를 영어로 번역한 리뷰 번역본 컬럼(buyerTranslationFeedback)을 활용했다.
문제 해결💓
먼저, CSV 파일에서 데이터를 로드하고 전처리하여 샘플 데이터를 반환하는 작업을 했다.
import pandas as pd
from sklearn.model_selection import train_test_split
from transformers import BertTokenizer
import torch
from torch.utils.data import Dataset, DataLoader
from transformers import BertForSequenceClassification, AdamW, get_linear_schedule_with_warmup
# 데이터 로드 및 전처리
def load_and_preprocess_data(filepath):
df = pd.read_csv(filepath, encoding='ISO-8859-1')
df['buyerTranslationFeedback'] = df['buyerTranslationFeedback'].fillna('')
df['Evaluation'] = pd.to_numeric(df['Evaluation'], errors='coerce')
df_sampled = df.sample(n=1000, random_state=42)
df_sampled['sentiment'] = df_sampled['Evaluation'].apply(label_sentiment)
return df_sampled
다음은 'Evaluation' 값을 기반으로 감정 레이블을 반환했다.
# 감정 라벨 정의
def label_sentiment(evaluation):
if evaluation >= 70:
return 2 # 긍정
elif evaluation < 30:
return 0 # 부정
else:
return 1 # 중립
그런 다음, 데이터를 학습 및 검증 세트로 분할하고, 텍스트를 토크나이징한다. 텍스트를 토크나이징하는 이유는 자연어를 기계 학습 모델이 이해할 수 있는 형태로 변환하기 위해서이다. 토크나이징은 문장을 단어, 서브워드 또는 문자 단위로 분할하는 과정이다.
# 데이터 분할 및 토크나이저 준비
def prepare_datasets(df_sampled):
train_texts, val_texts, train_labels, val_labels = train_test_split(
df_sampled['buyerTranslationFeedback'], df_sampled['sentiment'], test_size=0.2, random_state=42
)
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
train_encodings = tokenizer(list(train_texts), truncation=True, padding=True)
val_encodings = tokenizer(list(val_texts), truncation=True, padding=True)
return train_encodings, val_encodings, train_labels, val_labels, tokenizer
토크나이즈된 텍스트와 레이블을 포함하는 데이터셋을 정의한다.
# 데이터셋 클래스 정의
class ReviewDataset(Dataset):
def __init__(self, encodings, labels):
self.encodings = encodings
self.labels = labels
def __len__(self):
return len(self.labels)
def __getitem__(self, idx):
item = {key: torch.tensor(val[idx]) for key, val in self.encodings.items()}
item['labels'] = torch.tensor(self.labels[idx])
return item
BERT 모델을 로드하고 파라미터를 동결하며, 옵티마이저를 준비한다. 이 모델은 3개의 클래스(긍정, 중립, 부정)을 예측하도록 설정되어 있다. 파라미터를 동결하는 이유는 사전 학습된 가중치를 그대로 유지하면서 출력 레이어만 학습되도록 하기 위함이다. 이를 통해 학습 속도를 높이고, 더 적은 데이터로도 효과적인 학습을 수행할 수 있다.
# 모델 정의 및 학습 준비
def prepare_model():
model = BertForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=3)
for param in model.bert.parameters():
param.requires_grad = False
optimizer = AdamW(model.parameters(), lr=5e-5)
return model, optimizer
모델을 학습하고 검증하는 함수이다. 각 에포크(전체 데이터셋을 한 번 모두 사용하는 학습 단위)마다 학습 손실과 검증 손실 및 정확도를 출력하는 코드를 추가했다.
# 학습 및 검증 루프
def train_model(model, optimizer, train_loader, val_loader, device, epochs=2):
scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps=0, num_training_steps=len(train_loader) * epochs)
loss_fn = torch.nn.CrossEntropyLoss()
model.to(device)
for epoch in range(epochs):
model.train()
total_train_loss = 0
for batch in train_loader:
optimizer.zero_grad()
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
labels = batch['labels'].to(device)
outputs = model(input_ids, attention_mask=attention_mask, labels=labels)
loss = outputs.loss
total_train_loss += loss.item()
loss.backward()
optimizer.step()
scheduler.step()
avg_train_loss = total_train_loss / len(train_loader)
print(f"Epoch {epoch + 1}, Train Loss: {avg_train_loss}")
model.eval()
total_val_loss = 0
total_correct = 0
with torch.no_grad():
for batch in val_loader:
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
labels = batch['labels'].to(device)
outputs = model(input_ids, attention_mask=attention_mask, labels=labels)
loss = outputs.loss
total_val_loss += loss.item()
logits = outputs.logits
_, preds = torch.max(logits, dim=1)
total_correct += torch.sum(preds == labels)
avg_val_loss = total_val_loss / len(val_loader)
accuracy = total_correct.double() / len(val_dataset)
print(f"Epoch {epoch + 1}, Validation Loss: {avg_val_loss}, Accuracy: {accuracy}")
입력된 텍스트에 대해 감정을 예측하는 함수이다.
# 예측 함수
def predict_sentiment(model, tokenizer, text, device):
model.eval()
inputs = tokenizer(text, return_tensors='pt', truncation=True, padding=True)
inputs = {key: val.to(device) for key, val in inputs.items()}
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits
_, prediction = torch.max(logits, dim=1)
return prediction.item()
전체 실행 코드는 아래와 같다. review_text에 리뷰 내용을 넣으면 해당 텍스트가 부정적인지, 긍정적인지, 중립적인지 출력될 것이다.
# 전체 실행 코드
filepath = '(절대경로)'
df_sampled = load_and_preprocess_data(filepath)
train_encodings, val_encodings, train_labels, val_labels, tokenizer = prepare_datasets(df_sampled)
train_dataset = ReviewDataset(train_encodings, train_labels.tolist())
val_dataset = ReviewDataset(val_encodings, val_labels.tolist())
train_loader = DataLoader(train_dataset, batch_size=16, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=16, shuffle=False)
model, optimizer = prepare_model()
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
train_model(model, optimizer, train_loader, val_loader, device)
review_text = "This product is fantastic!"
predicted_sentiment = predict_sentiment(model, tokenizer, review_text, device)
sentiment_labels = {0: "Negative", 1: "Neutral", 2: "Positive"}
print(f"Review: {review_text}")
print(f"Predicted Sentiment: {sentiment_labels[predicted_sentiment]}")
출력 결과 :
Epoch 1, Train Loss: 0.9177849292755127
Epoch 1, Validation Loss: 0.5167489487391251, Accuracy: 0.965
Epoch 2, Train Loss: 0.5440291517972946
Epoch 2, Validation Loss: 0.3306535092683939, Accuracy: 0.965
Review: This product is fantastic!
Predicted Sentiment: Positive
첫 번째 에포크에는 상당한 오차를 가지고 있었다. 하지만 두 번째 에포크 학습에서는 오차가 줄어들었다. 정확도는 비교적 높은 상태를 유지하는 것 같다. 어쨋든, 현재 내가 쓴 "This product is fantastic!"라는 리뷰를 긍정적인 감정으로 분류하는 것보아 정상적으로 작동하는 것 같다.
하지만, 보완점은 몇 가지 있다.
1. 샘플링된 데이터는 1,000개
내가 시간을 줄이고자 비교적 작은 양의 데이터로만 학습을 시켰다. 따라서, 더 많은 데이터와 다양한 형태의 데이터를 수집해서 모델을 재학습하면 좋을 것 같다.
2. 실시간 처리 속도
내가 문제로 짚었던 라이브 댓글 필터링에서 쓰이기에는 많은 제약이 있다. 원활한 라이브 방송 상호작용을 통해서 속도가 중요한데 아직 많이 무거운 것 같다.
3. 현재 모델은 단순한 감정 분류만을 수행
댓글의 맥락이나 의도까지 이해하기에는 무리가 있는 것 같다. 부정적인 감정이지만 건설적인 비판을 담고 있는 댓글은 구별하기 어려울 것 같다.
4. 그냥 LLM으로 해결하자
사실 이렇게 할 필요없다. LLM에 넣고 내가 원하는 바를 요구하면 위와 같은 결과를 비슷하게 도출할 것이다.
마무리💫
실시간 댓글 필터링 시스템의 기초를 마련해보았다. 라이브 방송 중에 부적절한 댓글을 사전에 차단하여 방송의 질을 향상시킬 수 있게 하는 것이 목표였고 부분적으로 완수했다고 생각한다.
또한, 더 나아가 감정 분석 보델은 다양한 곳에도 활용 가능하니 오늘의 아이디어를 내일은 더 확장시키고자 한다. 예를 들어, 소셜 미디어 관리, 온라인 커뮤니티 내 질서 관리, 마케팅 등에서 유연하게 활용 가능할 것이라고 생각한다.
'My Work > Data Literacy' 카테고리의 다른 글
| 모두의 주차장 서비스 개선하기 feat. 피처 벡터 (0) | 2024.06.07 |
|---|---|
| 프로그래머스 연습문제 풀이 (0) | 2023.12.09 |
| 필수 SQL 개념 - (3/3편) (0) | 2023.11.30 |
| 필수 SQL 개념 - (2/3편) (0) | 2023.11.29 |
| 필수 SQL 개념 - (1/3편) (1) | 2023.11.28 |


