저번 글에 이어 설계한 로그 설계를 기반으로 영어 스피킹 앱 '스픽'에 적용해보겠다. 스픽의 저장 페이지는 사용자가 학습을 하면서 저장한 표현을 모아놓은 페이지이다. 이 페이지에서 내가 가장 불편하다고 느낀 점은 보관한 표현의 순이 최신 순이므로 내가 오랜 과거에 저장한 표현을 찾기 위해서는 스크롤을 많이 내려야 한다.

그래서 이러한 불편한 점을 개선하고자 임의로 '오래된 순', '발음이 안 좋은 순', '많이 복습한 순'의 필터 기능을 추가했다. 시간이 많이 지나서 오래된 표현을 다시 복습하고자 하는 유저는 '오래된 순' 필터 기능을 사용할 것이고, 본인이 발음이 안 좋아서 점수를 낮게 받은 영어 표현을 복습하고 하는 유저는 '발음이 안 좋은 순' 필터 기능을 사용할 것이고, 본인이 많이 복습한 영어 표현을 다시 복습하고자 하는 유저는 '많이 복습한 순' 필터 기능을 사용할 것이다.

추가된 3개의 필터 기능의 복습 전환율을 알아보고자 추가로 로그 설계를 아래 사진과 같이 했다.
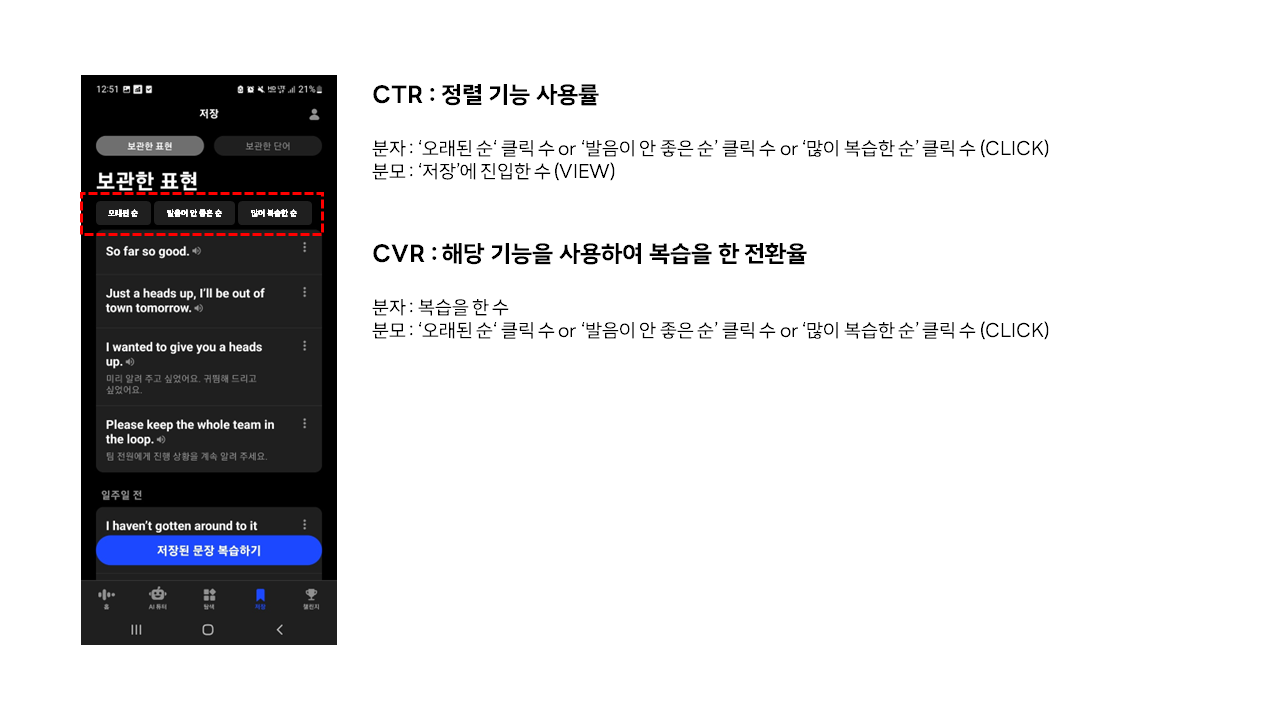
정렬 기능 사용률(CTR)은 아래와 같이 계산될 것이다.
- '오래된 순' 사용률 = '오래된 순' 클릭 수 / '저장'에 진입한 수
- '발음이 안 좋은 순' 사용률 = '오래된 순' 클릭 수 / '저장'에 진입한 수
- '많이 복습한 순' 사용률 = '오래된 순' 클릭 수 / '저장'에 진입한 수
복습 전환율(CVR)은 아래와 같이 계산될 것이다. 복습 전환율 같은 경우는 필터 기능을 적용한 후, 복습 여부에 따라 True, False로 값이 도출될 것이다.
- 복습을 한 수 / '오래된 순' 사용률
- 복습을 한 수 / '발음이 안 좋은 순' 사용률
- 복습을 한 수 / '많이 복습한 순' 사용률

위 이벤트가 추가되었고 예상되는 데이터 형태는 아래와 같다.

이런 식으로 데이터가 쌓이다보면 3개의 필터 기능에서 유저들이 자주 사용하는 필터 기능과 자주 사용하지 않는 필터 기능을 구별할 수 있다.
'My Work > Data Literacy' 카테고리의 다른 글
| AARRR 퍼널별 참고사항 (1) | 2023.11.14 |
|---|---|
| AB Test (핵심 요소, 규칙) (0) | 2023.11.13 |
| 데이터 로그 설계(Tracking Plan) (0) | 2023.11.11 |
| 데이터 로그 설계 (0) | 2023.11.07 |
| 지표 정의 2편 (지표 구성 요소) (0) | 2023.11.06 |



